Why did the Transformer model go to therapy?
Because it had trouble paying attention to its own emotions and kept getting lost in self-attention!
The Transformer model is a groundbreaking deep learning architecture that has had a profound impact on the field of natural language processing (NLP) and machine translation. It was introduced in 2017 in a seminal paper titled “Attention is All You Need” by Vaswani et al. Since then, it has become the preferred model for various sequence-to-sequence tasks, surpassing traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs).
At its core, the Transformer model employs a self-attention mechanism to capture interdependencies between different positions in a sequence. Unlike RNNs, which process sequential data sequentially, the Transformer can simultaneously process the entire sequence. This parallelization greatly improves training and inference efficiency, making it particularly adept at handling lengthy sequences.
The self-attention mechanism allows the Transformer to assign varying weights to different elements in a sequence when computing its representation. This enables the model to focus on the most relevant information by assigning attention scores based on each element’s relevance to others. Consequently, the Transformer can capture long-range dependencies and learn intricate relationships between sequence elements.
Positional encoding is another crucial aspect of the Transformer model. Since the model lacks an inherent understanding of element order in a sequence, positional encoding is incorporated into input embeddings. This encoding provides the model with information about the relative and absolute positions of elements within the sequence.
The Transformer model comprises an encoder and a decoder. In tasks such as machine translation, the encoder processes the input sentence, while the decoder generates the output sentence in the target language. Both the encoder and decoder consist of multiple layers of self-attention and feed-forward neural networks. This layering facilitates the model’s ability to capture increasingly abstract representations as information flows through the network.
Thanks to its capacity to handle long-range dependencies, parallelize computations, and effectively capture contextual information, the Transformer model has garnered widespread adoption in various NLP applications. It has achieved state-of-the-art results in machine translation, text summarization, question answering, sentiment analysis, and other tasks. The Transformer’s versatility, scalability, and powerful attention mechanism have solidified its position as a fundamental component of contemporary deep learning architectures in NLP.
Let’s first understand Self Attention —
Self-attention, also known as intra-attention or scaled dot-product attention, is a core component of the Transformer model, enabling it to capture long-range dependencies and contextual relationships between different positions in a sequence. Self-attention is employed within both the encoder and decoder sections of the Transformer architecture.
Here’s an in-depth breakdown of the self-attention mechanism in the Transformer:
By utilizing self-attention, the Transformer model can effectively capture global dependencies and model interactions between distant positions in the sequence. The attention mechanism enables the model to focus on different parts of the sequence dynamically, assigning higher weights to the most relevant positions for each query.
The self-attention mechanism, with its ability to model complex relationships and dependencies, plays a pivotal role in various natural language processing tasks. It allows the model to effectively process and represent sequential data, leading to improved performance in machine translation, sentiment analysis, text generation, and other tasks.
As we can see, Transformer is basically Encoder + Decoder,
So let’s understand each individually —

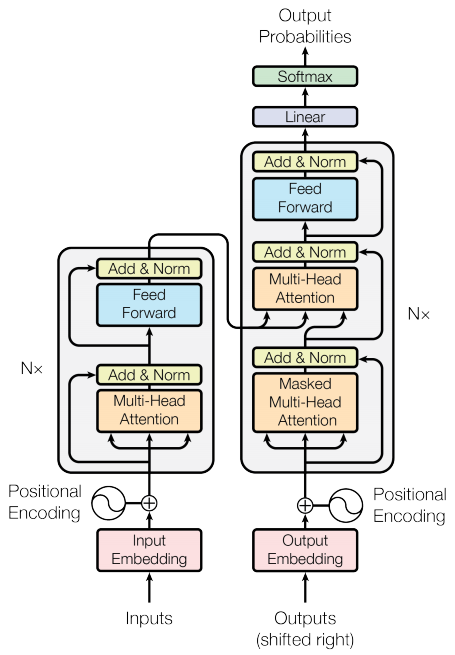
The part in the red box is basically the encoder. It has the following components —
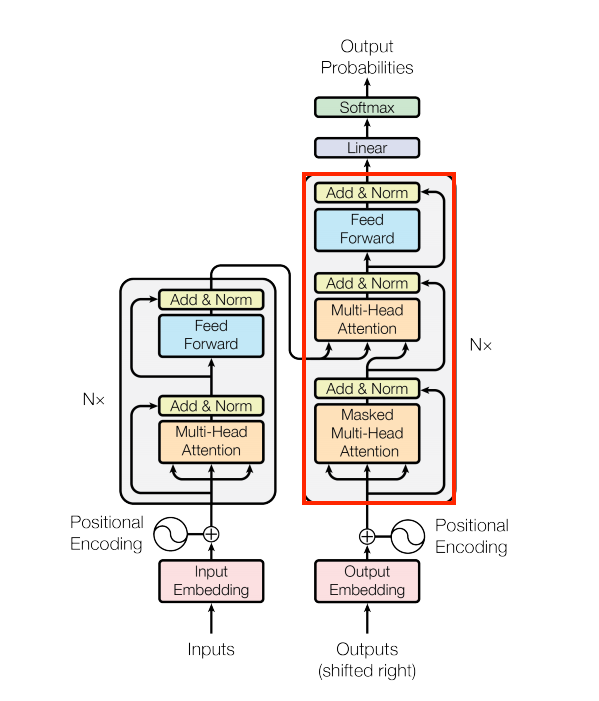
The part in the red box is basically the Decoder. It has the following components —
So basically, it has just one additional component than Encoder, and that is Masked Multi-Head Attention.
Masked Multi-Head Attention —
Within the Transformer model’s decoder, a modified version of multi-head attention known as “masked multi-head attention” is employed. It allows the model to attend selectively to previous positions in the target sequence during training, ensuring the autoregressive nature of the predictions.
The masked multi-head attention in the decoder consists of the following components:
Similar to the standard multi-head attention, masked multi-head attention computes attention scores by comparing the query vectors with the key vectors. These attention scores determine the importance of each source position for the current target position. The weighted sum of the value vectors, using the attention scores as weights, yields the attended output.

The feed-forward neural network —
It is a vital element within each layer of the Transformer model, present in both the encoder and decoder. It plays a crucial role in processing the representations generated by the self-attention mechanism and capturing complex interactions within the sequence.
Here are the key aspects and operations involved in the feed-forward neural network within the Transformer:
The feed-forward neural network enhances the representations generated by the self-attention mechanism, introducing non-linear transformations and enabling the model to capture complex relationships between elements in the sequence. By operating on each position independently, the network can capture local patterns and generate higher-level representations of the sequence.
To facilitate information flow and stabilize training, residual connections, and layer normalization are typically applied after the feed-forward neural network. Residual connections allow for the direct flow of information from the input to the output of the network, aiding in gradient propagation. Layer normalization helps normalize the representations, improving stability and performance.
So that’s some overview of the Transformer Neural Network.
There are many applications for it, which will post about in future blogs. So stay tuned.
With this, we come to a close to this blog. Did you like what you read? Would you like to know more about me? Well, guess what, I’m on LinkedIn so go ahead and reach out!
With ❤,
Jatin S.
Image Credit — https://www.tensorflow.org/